Version 0.0.9
International Anti-Copyright 2001-2002 by Matt Chisholm, matt (at) theory dot org

Version 0.0.9
International Anti-Copyright 2001-2002 by Matt Chisholm, matt (at) theory dot org
For a practical project, this page might be called a “Manual” instead of a “Manifesto.”
Alphabet Soup is a project which attempts to determine a number of things about the shapes of letters in several different writing systems. First, it hypothesizes a set of basic building blocks that all letters are built up from. Second, it hypothesizes a set of rules, a grammar or syntax, which defines how those pieces combine to make different letters.
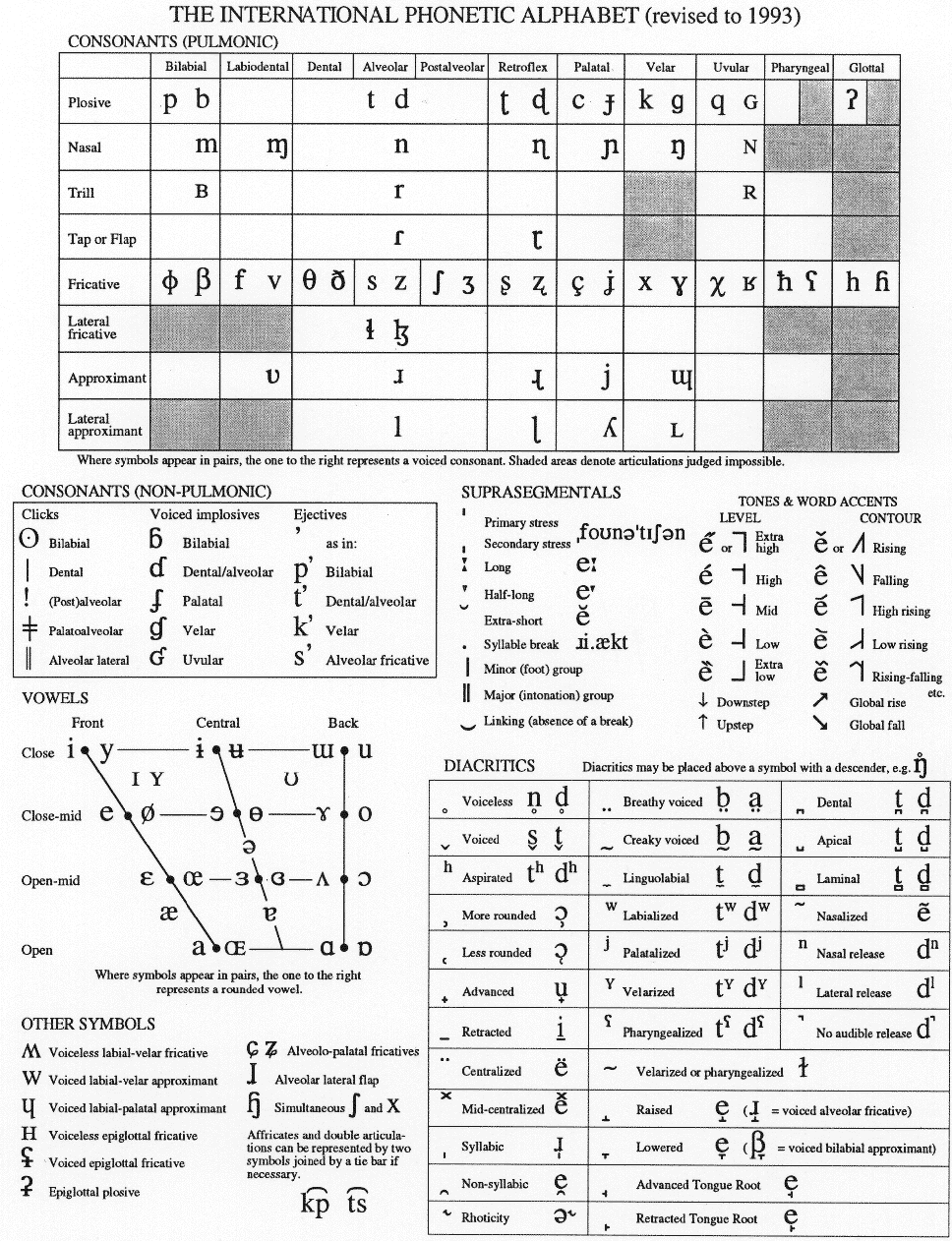
The project will eventually include the letters in the Roman alphabet, upper and lower case Arabic numbers, the Cyrillic alphabet, the International Phonetic Alphabet, and much of the uppercase Greek alphabet. It currently has the capability to generate 2,099,776 letter-like symbols, most of which are not in any alphabet, although they look quite plausible.
Alphabet Soup is implemented in a computer program which uses the building blocks and grammar to do several things. It can generate individual letters. It can take a input string and randomly vary the letters, producing a string which is readable but strange looking. Or it can generate random strings of symbols. The program includes an optical kerning algorithm to ensure that the letters are kerned sensibly.
The syntactic rules, which describe how to put the pieces together, is a system of context-free rules. This is the same type of system which is used for explaining phrase structure in modern linguistics. From a linguistic point of view, this project could be informally thought of as Universal Grammar for European orthography.
The syntax can be extended, potentially allowing the program to generate additional letters, or entirely different alphabets.
A syntactic rule consists of a start state, and a list of states which can be drawn and added to that state. Each state in the list of states comes with information about whether it should be reflected horizontally or vertically, and with information specifying how far vertically and horizontally it should be moved before adding it to the current state. This allows, for example, the curly tail seen in `f,' `j,' `c,' and `r' to be the same state, drawn at different locations after it has been flipped horizontally and/or vertically.
Each symbol that the system produces is described by a ``tree,'' a mathematical object produced by the application of the syntactic rules. If the system is given an incomplete tree, one where some terminal nodes in the tree are not terminal nodes in the syntax, the system randomly generates subtrees to fill in the ``underspecified'' terminal nodes. This is how it can randomize a prespecified letterform.
The pieces which comprise the letters are of my own design, and are reminiscent of a standard serif font, like Times. Part of my inspiration for this system comes from my experience designing typefaces. While designing typefaces, I would always reach a point where it seemed that any unfinished letters could be built up algorithmically from pieces of already existing, ``basic'' letters, like `o,' `l,' `n,' and `x.' This project is an expression of that realization that typefaces could be generated algorithmically.
To this end, the images containing the pieces can be replaced, allowing the program to generate letters in a different typeface. The system could eventually become a new framework for typeface design.
Finally, the syntax and the images could be replaced, and the program could be used to generate completely different images. One person suggested building images of insects from pieces.
The program, which is relatively short, is written in the Python programming language and uses the python-imaging module to create the composite images. It should work without any modification on any UNIX system with these programs installed. I haven't the faintest idea if it works on MacOS or Windows; let me know what happens if you try it out.
The source code of the compiler/interpreter, the syntax, and the building block images in this project are all released under the GNU GPL.
The latest implementation will be available from this page.
There are a great many symbols and characters which are generally associated with typefaces (and indeed, many included in ASCII and all in Unicode). I have made the choice to leave out some things from this system:
There are many different potential roles for this program:
{kind=link}
{kind=link}
{kind=link}
{kind=link}